
Executive Summary
Most AI comparison charts are not wrong. They are just not useful.
They conflate products with models, capabilities with positioning, and architecture with marketing narrative. The result is a category of content that generates traffic but rarely guides decisions.
This piece reframes the comparison around something more durable: how these systems are actually built, and where the real differences lie.
Table of Contents
- Executive Summary
- The structural problem
- Where the real differences are
- Architecture vs marketecture
- Further reading
- The right question
The structural problem
When someone asks “which AI is best,” they are usually comparing brands. But underneath each branded AI product is a layered system: an interface, an orchestration layer, a model, a retrieval mechanism, integration points, and a governance layer. Most comparisons skip all of that and jump straight to a verdict.
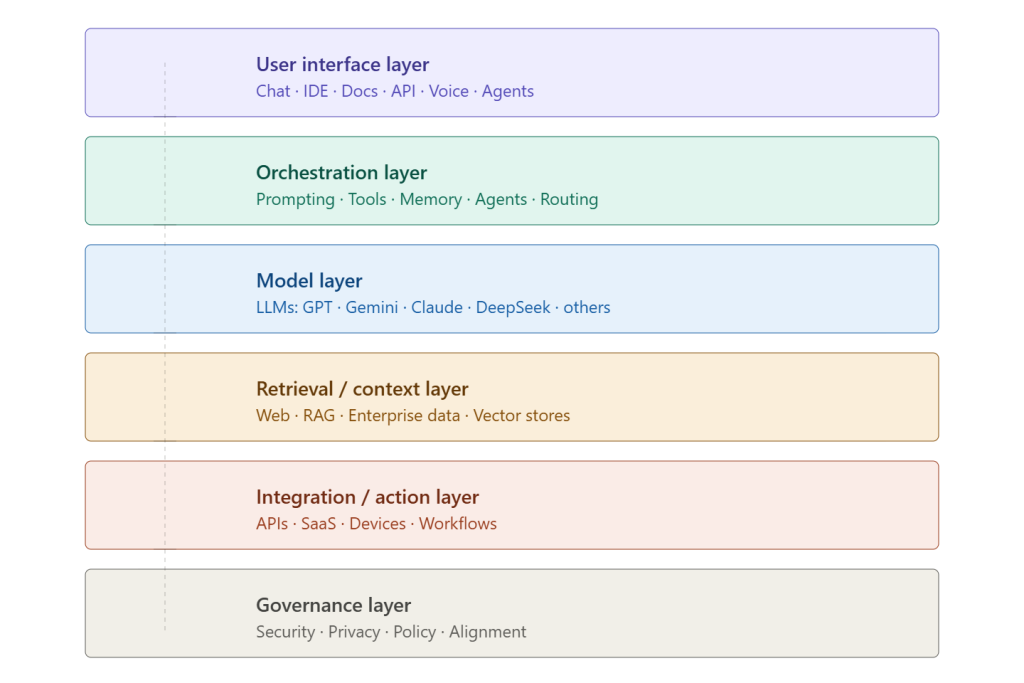
The consequence of ignoring this structure is confusion. Perplexity, for example, is frequently described as an AI research tool — but it is best understood as a retrieval-first assistant with model access layered underneath. The value it provides is in search, citation, and interface design, not in raw intelligence. Conflating the two leads to poor tool selection.
The same issue applies to Copilot. There is no single “Copilot.” There is M365 Copilot, GitHub Copilot, Security Copilot, Copilot Studio — each running different models, in different contexts, with different capabilities. Treating it as a single comparable entity produces meaningless comparisons.
Where the real differences are
Once you map each system to its architectural layers, a clearer picture emerges.
The differences between frontier models on standard benchmarks — MMLU, HumanEval, BIG-bench — are real but narrowing. What diverges significantly is everything around the model: orchestration capability, ecosystem integration, retrieval approach, and governance posture.
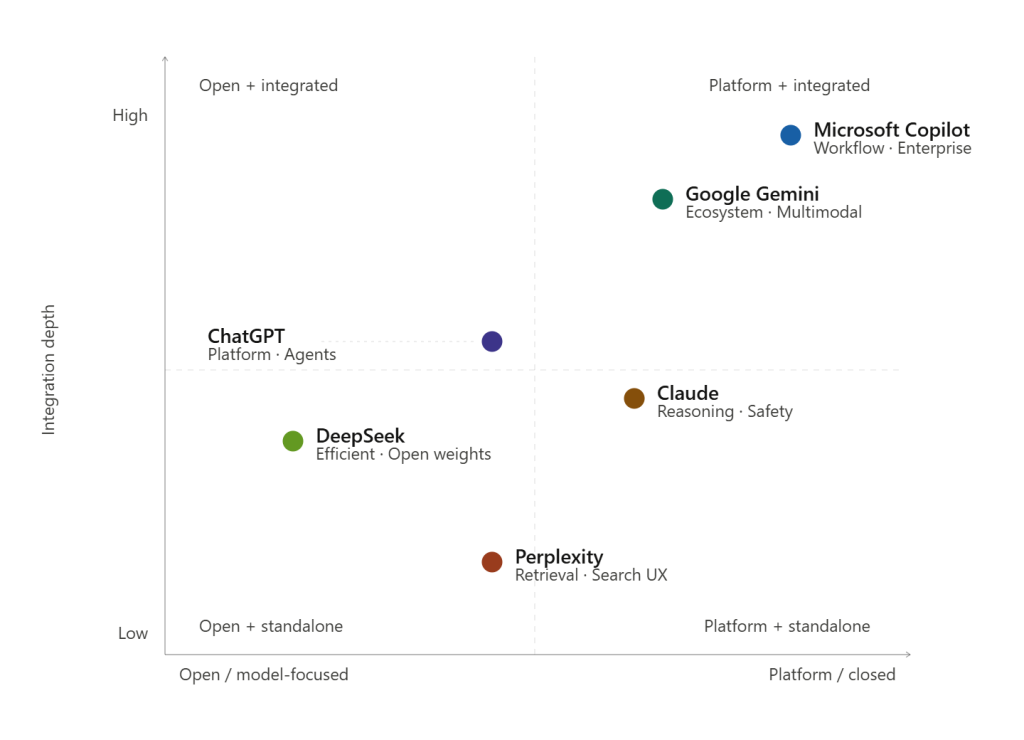
That is where the strategic positioning actually lives. OpenAI’s ChatGPT is often perceived as strong in orchestration and tool use, though that judgment depends on the workflow being measured. Google’s advantage is data and context breadth. Microsoft’s is enterprise workflow depth. Anthropic is often positioned around structured reasoning, safety, and alignment. DeepSeek is the cost-efficiency play. Perplexity is a retrieval product wearing a model product’s clothes. It is more retrieval-centric than model-centric in how many users experience it.
Architecture vs marketecture
There is a useful boundary rule here. If a capability claim cannot be mapped to a specific architectural layer, a reproducible benchmark, or a measurable workflow outcome — it is marketecture.
“Best for research.” “Most intelligent.” “Replaces all other tools.” These are narrative positions, not architectural facts.
The technically honest framing is contextual: which layer of this architecture does my problem actually require? If the answer is deep enterprise workflow integration, the Microsoft stack is often a natural first choice. If the answer is cost-efficient inference at scale, DeepSeek is worth evaluating seriously. If the answer is long-document analysis with controlled output, Claude is a reasonable fit.
Further reading
- Perplexity architecture and retrieval-first design
- Microsoft Copilot product family documentation
- Microsoft documentation for Microsoft 365 Copilot, GitHub Copilot, Security Copilot, and Copilot Studio.
- DeepSeek efficiency reporting
- Claude long-context and document analysis references
- AI assistant reliability and hallucination research
- AI assistants misrepresent news content 45% of the time [Oct-25, May-26]
- Agent orchestration and ecosystem frameworks
The right question
The comparison question most people ask — which AI is best? — is not quite answerable, because it is not quite the right question.
The question that produces useful answers is: which architecture fits the problem?
That reframe is not a dodge. It is the difference between choosing a tool and choosing a category.